Provide LLM Service with Inference Module for AI Application
In the wave of Artificial Intelligence (AI), Large Language Models (LLMs) are gradually becoming a key factor in driving innovation and productivity. As a result, researchers and developers are looking for a more efficient way to deploy and manage complex LLM models and AI applications.
To simplify the process from model construction, deployment and interaction with applications, the KusionStack community has provided an inference module. We will explore in detail how to deploy an AI application using LLM service provided by this module in this article.
The module definition and implementation, as well as the example application we are about to show can be found here.
Prerequisites
Before we begin, we need to perform the following steps to set up the environment required by Kusion:
- Install Kusion
- Running Kubernetes cluster
For more details, please refer to the prerequisites in the guide for deploying an application with Kusion.
Initializing and Managing Workspace Configuration
For information on how to initialize and switch a workspace with kusion workspace create and kusion workspace switch, please refer to this document.
For the current version of the inference module, an empty configuration for workspace initialization is enough, and users may need to configure the network module as an accessory to provide the network service for the AI application, whose workload is described with service module. Users can also add other modules' platform configurations in the workspace according to their need.
An example is shown below:
modules:
service:
path: oci://ghcr.io/kusionstack/service
version: 0.2.0
configs:
default: {}
network:
path: oci://ghcr.io/kusionstack/network
version: 0.2.0
configs:
default: {}
inference:
path: oci://ghcr.io/kusionstack/inference
version: 0.1.0-beta.4
configs:
default: {}
Example
After creating and switching to the workspace shown above, we can initialize the example Project and Stack with kusion project create and kusion stack create. Please refer to this document for more details.
The directory structure, and configuration file contents of the example project is shown below:
example/
.
├── default
│ ├── kcl.mod
│ ├── main.k
│ └── stack.yaml
└── project.yaml
project.yaml:
name: example
stack.yaml:
name: default
kcl.mod:
[dependencies]
kam = { git = "https://github.com/KusionStack/kam.git", tag = "0.2.0" }
service = {oci = "oci://ghcr.io/kusionstack/service", tag = "0.1.0" }
network = { oci = "oci://ghcr.io/kusionstack/network", tag = "0.2.0" }
inference = { oci = "oci://ghcr.io/kusionstack/inference", tag = "0.1.0-beta.4" }
main.k:
import kam.v1.app_configuration as ac
import service
import service.container as c
import network as n
import inference.v1.inference
inference: ac.AppConfiguration {
# Declare the workload configurations.
workload: service.Service {
containers: {
myct: c.Container {image: "kangy126/app"}
}
replicas: 1
}
# Declare the inference module configurations.
accessories: {
"inference": inference.Inference {
model: "llama3"
framework: "Ollama"
}
"network": n.Network {ports: [n.Port {
port: 80
targetPort: 5000
}]}
}
}
In the above example, we configure the model and framework item of the inference module, which are two required configuration items for this module. The inference service of different models with different inference frameworks could be quickly built up by changing these two configuration items.
As for how the AI application use the LLM service provided by the inference module, an environment variable named INFERENCE_URL will be injected by the module and the application can call the LLM service with the address.
There are also some optional configuration items in the inference module for adjusting the LLM service, whose details can be found here.
Deployment
Now we can generate and deploy the Spec containing all the relevant resources the AI application needs with Kusion.
First, we should navigate to the folder example/default and execute the kusion generate command, and a Spec will be generated.
➜ default git:(main) ✗ kusion generate
✔︎ Generating Spec in the Stack default...
resources:
- id: v1:Namespace:example
type: Kubernetes
attributes:
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: example
spec: {}
status: {}
extensions:
GVK: /v1, Kind=Namespace
- id: apps/v1:Deployment:example:example-default-inference
type: Kubernetes
attributes:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: inference
app.kubernetes.io/part-of: example
name: example-default-inference
namespace: example
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: inference
app.kubernetes.io/part-of: example
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: inference
app.kubernetes.io/part-of: example
spec:
containers:
- env:
- name: INFERENCE_URL
value: ollama-infer-service
image: kangy126/app
name: myct
resources: {}
status: {}
dependsOn:
- v1:Namespace:example
- v1:Service:example:ollama-infer-service
- v1:Service:example:example-default-inference-private
extensions:
GVK: apps/v1, Kind=Deployment
kusion.io/is-workload: true
- id: apps/v1:Deployment:example:ollama-infer-deployment
type: Kubernetes
attributes:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
name: ollama-infer-deployment
namespace: example
spec:
selector:
matchLabels:
accessory: ollama
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
accessory: ollama
spec:
containers:
- command:
- /bin/sh
- -c
- |-
echo 'FROM llama3
PARAMETER top_k 40
PARAMETER top_p 0.900000
PARAMETER temperature 0.800000
PARAMETER num_predict 128
PARAMETER num_ctx 2048
' > Modelfile && ollama serve & OLLAMA_SERVE_PID=$! && sleep 5 && ollama create llama3 -f Modelfile && wait $OLLAMA_SERVE_PID
image: ollama/ollama
name: ollama-infer-container
ports:
- containerPort: 11434
name: ollama-port
resources: {}
volumeMounts:
- mountPath: /root/.ollama
name: ollama-infer-storage
volumes:
- emptyDir: {}
name: ollama-infer-storage
status: {}
dependsOn:
- v1:Namespace:example
- v1:Service:example:ollama-infer-service
- v1:Service:example:example-default-inference-private
extensions:
GVK: apps/v1, Kind=Deployment
- id: v1:Service:example:ollama-infer-service
type: Kubernetes
attributes:
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
accessory: ollama
name: ollama-infer-service
namespace: example
spec:
ports:
- port: 80
targetPort: 11434
selector:
accessory: ollama
type: ClusterIP
status:
loadBalancer: {}
dependsOn:
- v1:Namespace:example
extensions:
GVK: /v1, Kind=Service
- id: v1:Service:example:example-default-inference-private
type: Kubernetes
attributes:
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: inference
app.kubernetes.io/part-of: example
name: example-default-inference-private
namespace: example
spec:
ports:
- name: example-default-inference-private-80-tcp
port: 80
protocol: TCP
targetPort: 5000
selector:
app.kubernetes.io/name: inference
app.kubernetes.io/part-of: example
type: ClusterIP
status:
loadBalancer: {}
dependsOn:
- v1:Namespace:example
extensions:
GVK: /v1, Kind=Service
secretStore: null
context: {}
Next, we can execute the kusion preview command and review the resource three-way diffs for a more secure deployment.
➜ default git:(main) ✗ kusion preview
✔︎ Generating Spec in the Stack default...
Stack: default
ID Action
v1:Namespace:example Create
v1:Service:example:ollama-infer-service Create
v1:Service:example:example-default-inference-private Create
apps/v1:Deployment:example:example-default-inference Create
apps/v1:Deployment:example:ollama-infer-deployment Create
Which diff detail do you want to see?:
> all
v1:Namespace:example Create
v1:Service:example:ollama-infer-service Create
v1:Service:example:example-default-inference-private Create
apps/v1:Deployment:example:example-default-inference Create
Finally, execute the kusion apply command to deploy the related Kubernetes resources.
➜ default git:(main) ✗ kusion apply
✔︎ Generating Spec in the Stack default...
Stack: default
ID Action
v1:Namespace:example Create
v1:Service:example:ollama-infer-service Create
v1:Service:example:example-default-inference-private Create
apps/v1:Deployment:example:ollama-infer-deployment Create
apps/v1:Deployment:example:example-default-inference Create
Do you want to apply these diffs?:
> yes
Start applying diffs ...
✔︎ Succeeded v1:Namespace:example
✔︎ Succeeded v1:Service:example:ollama-infer-service
✔︎ Succeeded v1:Service:example:example-default-inference-private
✔︎ Succeeded apps/v1:Deployment:example:ollama-infer-deployment
✔︎ Succeeded apps/v1:Deployment:example:example-default-inference
Apply complete! Resources: 5 created, 0 updated, 0 deleted.
Testing
Execute the kubectl get all -n example command, and the deployed Kubernetes resources will be shown.
➜ ~ kubectl get all -n example
NAME READY STATUS RESTARTS AGE
pod/example-dev-inference-5cf6c74574-7w92f 1/1 Running 0 2d6h
pod/mynginx 1/1 Running 0 2d6h
pod/ollama-infer-deployment-7c56845496-s5snb 1/1 Running 0 2d6h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/example-dev-inference-public ClusterIP 192.168.116.121 <none> 80:32693/TCP 2d6h
service/ollama-infer-service ClusterIP 192.168.28.208 <none> 80/TCP 2d6h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/example-dev-inference 1/1 1 1 2d6h
deployment.apps/ollama-infer-deployment 1/1 1 1 2d6h
NAME DESIRED CURRENT READY AGE
replicaset.apps/example-dev-inference-5cf6c74574 1 1 1 2d6h
replicaset.apps/ollama-infer-deployment-7c56845496 1 1 1 2d6h
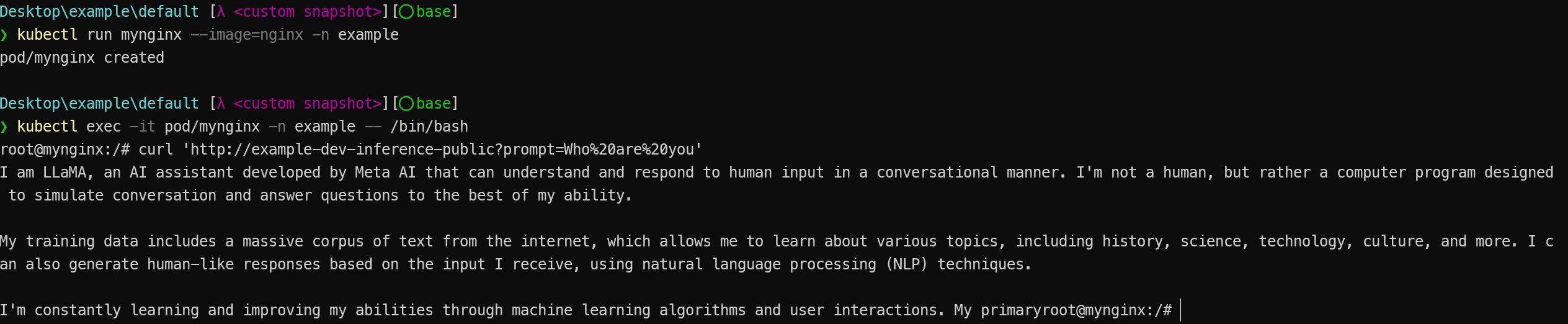
The AI application in the example provides a simple service that returns the LLM responses when sending a GET request with the prompt parameter.
We can run a new pod (such as nginx) in the same cluster and send requests to the AI application's service to perform a simple test. The relevant commands and test results are as follows:
kubectl run mynginx --image=nginx -n example
kubectl exec -it pod/mynginx -n example -- /bin/bash
# mynginx
curl 'http://example-dev-inference-public?prompt=Who%20are%20you'